|
GPU-based Massively parallel motion planning algorithms under uncertainty using POMDP
Download
1. Accepted in International Journal of Robotics Research (IJRR) 2015 in
2. Publication in International Conference on Robotics and Automation (ICRA) 2013 in
Abstract
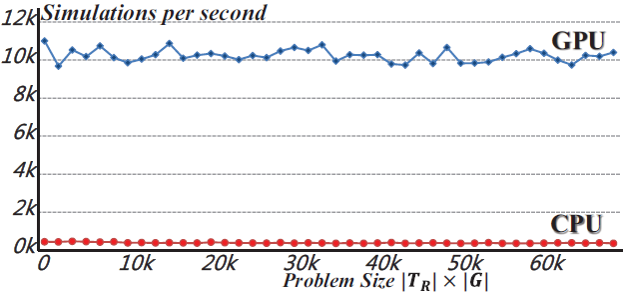
We present new parallel algorithms that solve continuous-state partially observable Markov decision process (POMDP) problems using the GPU (gPOMDP) and a hybrid of the GPU and CPU (hPOMDP). We choose the Monte Carlo value iteration (MCVI) method as our base algorithm and parallelize this algorithm using the multi-level parallel formulation of MCVI. For each parallel level, we propose efficient algorithms to utilize the massive data parallelism available on modern GPUs. Our GPU-based method uses the two workload distribution techniques, compute/data interleaving and workload balancing, in order to obtain the maximum parallel performance at the highest level. Here we also present a CPU-GPU hybrid method that takes advantage of both CPU and GPU parallelism in order to solve highly complex POMDP planning problems. The CPU is responsible for data preparation, while the GPU performs Monte Cacrlo simulations; these operations are performed concurrently using the compute/data overlap technique between the CPU and GPU. To the best of the authors' knowledge, our algorithms are the first parallel algorithms that efficiently execute POMDP in a massively parallel fashion utilizing the GPU or a hybrid of the GPU and CPU. Our algorithms outperform the existing CPU-based algorithm by a factor of 75~99 based on the chosen benchmark.
Overview
• a GPU-based method (gPOMDP) for solving POMDP planning problems with a moderate complexity as well as a CPU-GPU hybrid method (hPOMDP) for solving more complicated POMDP planning problems. • Solve continuous-state POMDP problems • Present two workload distribution techniques of the compute/data interleaving technique and workload balancing using the paradigm of gathering, scheduling and running (GSR) • gPOMDP and hPOMDP outperform the existing CPU-based algorithm by a factor of 75~99 based on the chosen benchmark Algorithms • POMDP-based MCVI
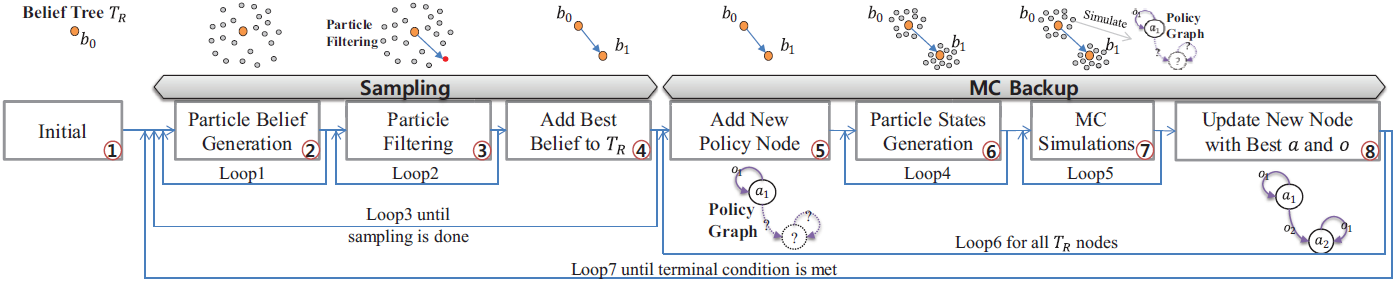
The algorithm samples a new belief node that is reachable from the initial belief node using a particle-filtering method. Then, it updates the policy graph using the MCVI method. Note that many loops are required to identify the best node, best policy graph action and best observation. • gPOMDP: GPU multi-level POMDP-based parallel algorithm
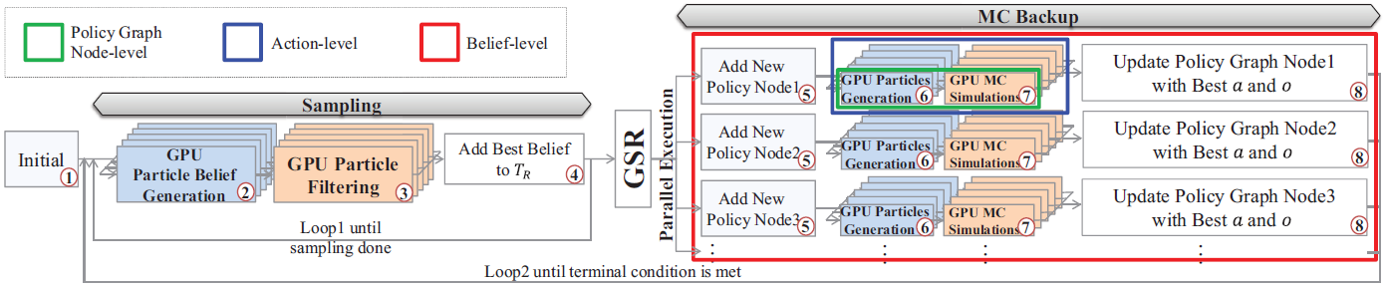
The step numbers are matched with those in Figure 1, and the multiply layered boxes of each step indicate parallel execution. The green, blue, and red boxes indicate policy graph node-, action-, and belief-level parallelisms, respectively. Note that, in gPOMDP, five loops are eliminated from the process shown in Figure 1. • hPOMDP: CPU-GPU POMDP-based hybrid algorithm
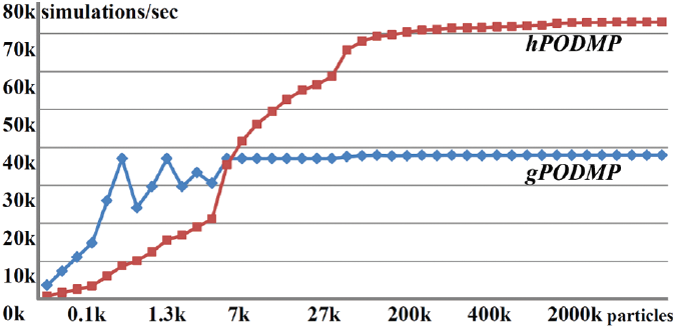
The step numbers are matched with those in Figure 2. hPOMDP generates particles on the CPU side in order to maximize the utilization rate of the GPU. When the number of particles is less than 7000 and the complexity of the benchmark is low, GPU particle generation can compensate for CPU-GPU data transfer; however, it is more efficient to generate particles in the CPU when the number of particles is greater than 7000 and the complexity of the benchmark is high because the particle simulation time exceeds the particle generation and upload time. Benchmarks
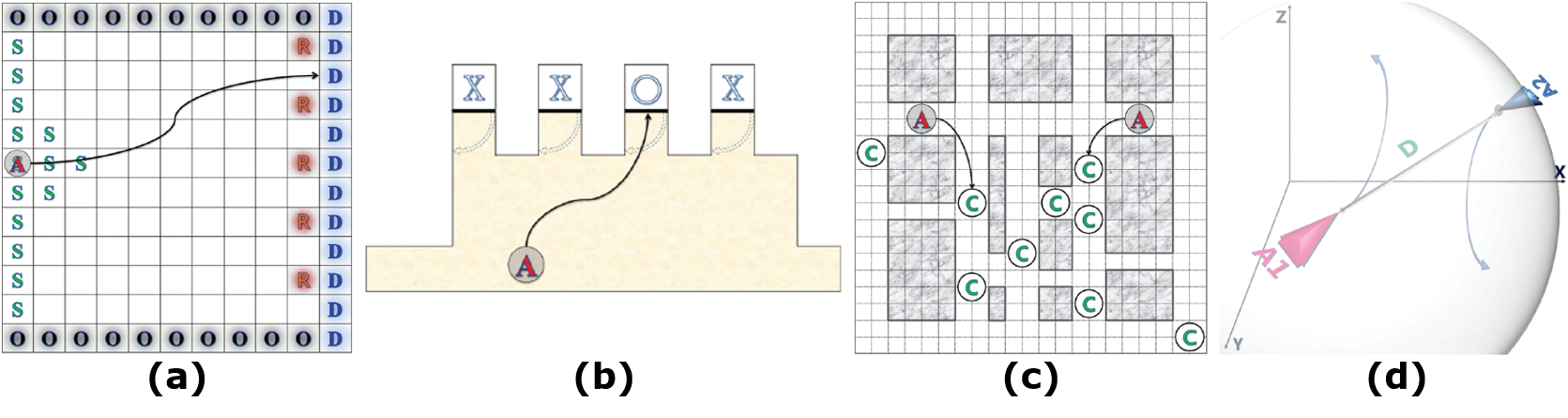
Underwater navigation (Figure 4(a)) : The agent receives a positive reward when it reaches the destination "D" while it receives the negative reward when it encounters the rock "R" or takes an action for moving. A robot starts from an initial point among "S" marks and tries to reach the destination "D" by taking actions for moving. The robot can localize itself only at the bottom or top of the map at "O" marks. Corridor (Figure 4(b)) : The robot navigates a corridor with four doors. The goal is to enter the second door from the right "O" mark. The robot receives a positive reward when it enters the target door while receiving a negative reward when entering wrong door "X" mark or moving beyond both ends of the corridor. Herding (Figure 4(c)) : Two robots track 12 escaped crocodiles in a 21X21 grid map with obstacles. The robots have to collaborate with each other to catch the crocodiles and are centrally controlled. The robots receive a positive reward when they successfully capture a crocodile. Aircraft (Figure 4(d)) : Two unmanned aircrafts try to avoid collision by maintaining a minimum safety distance from each other. Each aircraft receives a negative reward when the distance between them falls below the safety distance. This benchmark is defined in 3D continuous space, and the movement of each aircraft is calculated using 12 parameters including the 3D position (x, y, z), heading angle Θ, and horizontal and vertical speed (u, v) of two aircrafts. This benchmark has a higher complexity than the other 3 benchmarks because it works in 3D space rather than 2D space and uses 12 parameters, while the others use no more than 4 parameters. Result
Related Links APPL : Approximate POMDP Planning ToolKit |
|||||
|