All the experiments were conducted on Intel’s i9-13900K CPU with 64 GB of RAM and NVIDIA’s RTX 4090 GPU. We used DirectX’s DXR as a ray-tracing API with the Microsoft Visual Studio 2017 C++ programming language under 64-bit Windows 10.

Table.I. DATASET STATISTICS

Fig.2. PVM results of OctoMap-RT. The voxels are color-coded depending on the vertical height from the floor, and the dimension of each voxel is 10cm3.
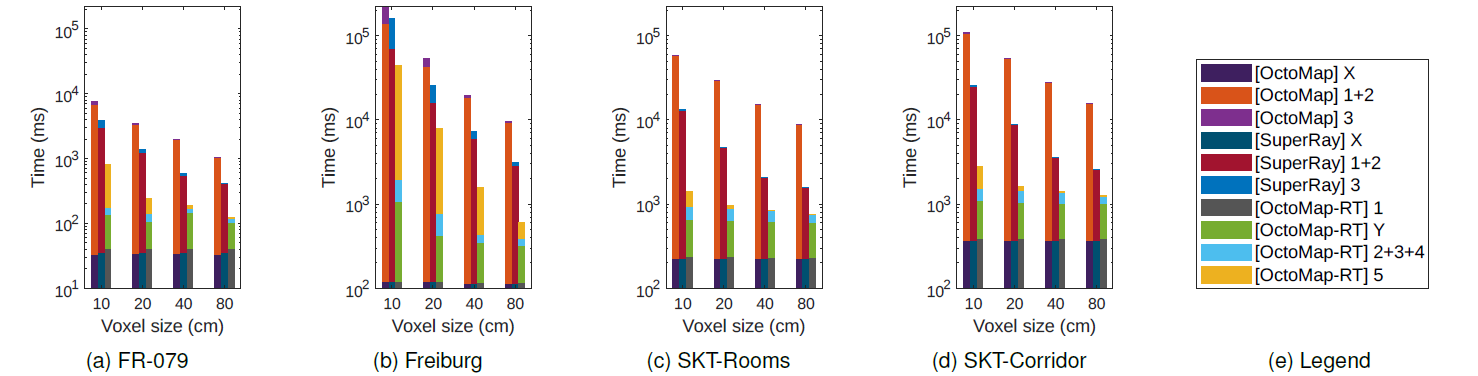
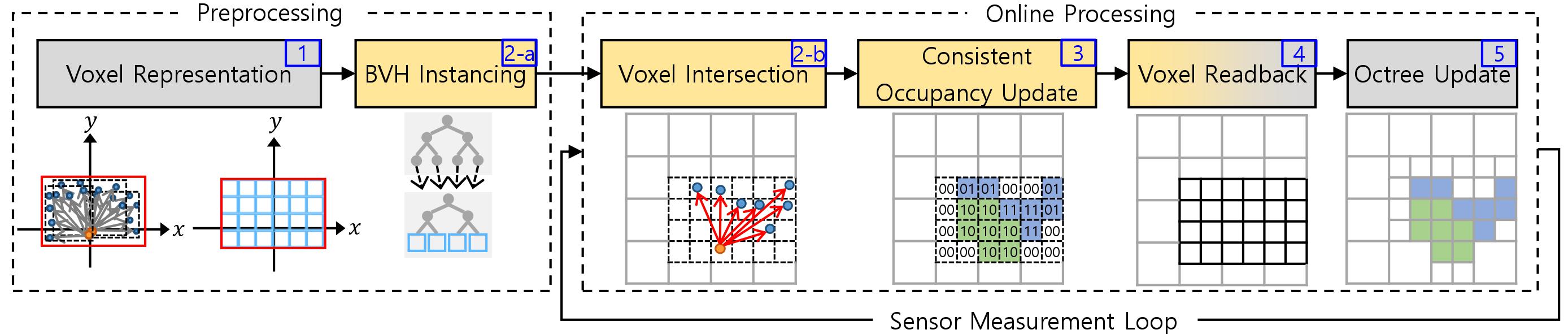
Fig.3. Performance breakdown of OctoMap-RT and its comparisons against OctoMap and SuperRay in log scale with various voxel dimensions using the datasets. For OctoMap and SuperRay, the labels in the stacked bars represent the times for ray data preparation (X), ray-shooting (1), consistent occupancy update (2), and octree update (3), respectively. For OctoMap-RT, the labels in the stacked bars represent the times for voxel representation (1, CPU), voxel/ray data upload (Y, from CPU to GPU), voxel intersection (2, GPU), consistent occupancy update (3, GPU), voxel readback (4, from GPU to CPU), and octree update (5, CPU), respectively.
The average performance in building PVMs using OctoMap-RT compared with OctoMap improved by a factor of 10.7, 10.1, 25.4, and 26.2, respectively, as shown in Fig. 2a, 2b, 2c, and 2d. OctoMap-RT is also 4.2, 4.1, 4.7, and 4.9 times faster than SuperRay in Fig. 2a, 2b, 2c, and 2d.
Fig.4. Number of free/occupied voxels generated using OctoMap (O) vs. OctoMap-RT (RT) using the benchmarks in Fig. 7. (a) 649K/126K vs. 651K/125K. (b) 84M/3.2M vs. 85M/3.1M. (c) 209K/99.3K vs. 210K/99.2K. (d) 460K/232.5K vs. 461K/232.1K.
OctoMap-RT builds the PVM with more voxels than are used in OctoMap, particularly with more free voxels. Fig. 4 supports this finding using the datasets in Fig. 2 with a voxel size of 10 cm. The leaf-level voxels consist of occupied and free voxels. Compared with OctoMap and SuperRay, on average, OctoMap-RT has 0.52% more leaflevel voxels in total, 0.59% fewer occupied voxels, and 0.65% more free voxels.

Table.II. COMPARISONS OF THE GPU MEMORY USAGE IN SHARED BVH
BVH instancing has effectively mitigated memory consumption for the large-scale outdoor environment. For instance, when the voxel size is 10cm, even though the shared ray space of Freiburg is 87.5 times larger than that of SKT-Rooms, as shown in Table I, the shared BVH’s memory of the former is 5.8 times even smaller than that of the latter.
Ewha Graphics Lab
Department of Computer Science & Engineering, Ewha Womans University
52, Ewhayeodae-gil, Seodaemun-gu, Seoul, Korea,
03760
+82-2-3277-6798
Heajung Min, hjmin@ewhain.net
Kyung Min Han, hankm@ewha.ac.kr
Young J. Kim, kimy@ewha.ac.kr